Generativ AI har rast gjennom hype-syklusen, og mange virksomheter begynner nå å erfare at teknologien ikke automatisk skaper verdi. I følge MIT så mislykkes 95% av organisasjoner med adopsjon av AI, så hvordan bygger vi egentlig løsninger som skalerer?

AI feiler sjelden på grunn av teknologien, men på grunn av organisasjonen
Tidligere i år publiserte MIT en ganske så knusende rapport om virksomheters AI-løsninger. De åpner knallhardt med følgende påstand:
«Despite $30–40 billion in enterprise investment into GenAI, this report uncovers a surprising result in that 95% of organizations are getting zero return» (State of AI in Business 2025, MIT Nanda ).
Ikke nok med påstanden om at 95 % av virksomheter mislykkes, det meldes også at over halvparten av AI-budsjettene går til salgs- og markedsføringstiltak, selv om de største gevinstene ofte ligger i backoffice-prosesser. Samtidig rapporteres det om betydelig høyere suksessrate når man kjøper verktøy, fremfor å bygge dem selv.
Problemet er imidlertid ikke modellene, men læringsgapet mellom teknologi og organisasjon. Man kan sitte med både kompetanse, domeneeksperter og infrastruktur for å bygge gode løsninger, men det hjelper lite hvis løsningene ikke lærer og tilpasser seg over tid. Betyr dette at man bør slutte å bygge selv? Tvert imot, men vi må begynne å tenke annerledes om hvordan vi bygger og forvalter AI-løsninger.
Kartverkets vei inn i KI
I 2024 gjennomførte Kartverket et innsiktsarbeid for å identifisere områder hvor AI kunne skape verdi. Kartverkets kundesenter pekte seg ut som et egnet sted å starte. Kundesenteret tar imot et stort volum av henvendelser om tinglysning på e-post og chat, med en voksende backlogg. Mange av sakene faller inn under de samme temaene. Informasjonen som brukes for å svare ut sakene ligger i stor grad åpent tilgjengelig på Kartverkets nettsider, men domenet er stort, detaljert og faglig komplekst. Selv om forutsetningene for å bruke generativ AI er gode, fordi spørsmålene ofte er gjentakende og datagrunnlaget relativt godt strukturert, er det likevel usikkert hvor anvendbar teknologien faktisk er i et domene som er såpass komplekst.
Det ble valgt en POC-tilnærming med noen prinsipper:
- Start med et gjennomførbart case
- Raskt måle verdi for å vurdere videre skalering
- Involver brukerne så tidlig som mulig
Resultatet ble en pilot for AI-assistert kundeservice, med en LLM-løsning der mennesker alltid verifiserer svar før det går tilbake til innsender («human in the loop»).
Nøkkelen til kvalitet er brukere og data
To faktorer viste seg å være avgjørende:
1. Tidlig og kontinuerlig brukerinvolvering
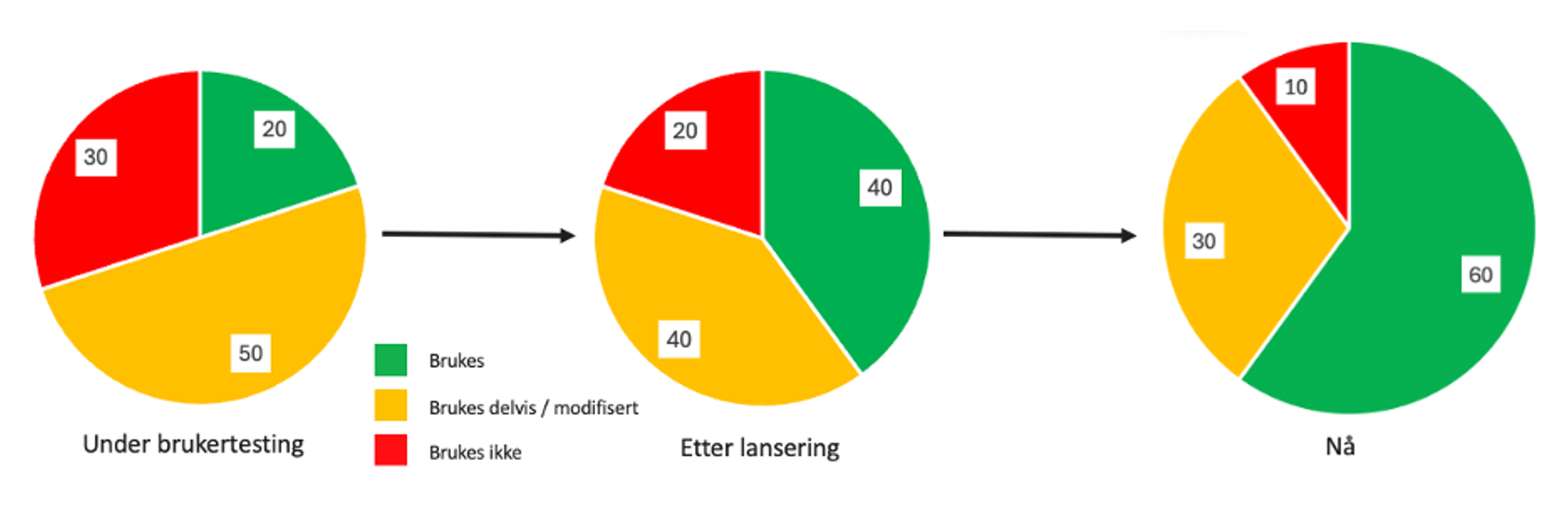
Brukerne måtte inn tidlig. Kontinuerlige tilbakemeldinger fra kundebehandlere formet hvordan løsningen oppførte seg, hva den burde svare, og hvor den feilet. Gjennom to runder med brukertesting og tett oppfølging fra dedikerte superbrukere etter lansering, fikk teamet jevn tilgang på innsikt som ellers ville tatt måneder å avdekke. Dette bygget både tillit og felles forståelse, og var avgjørende for å styre utviklingen i riktig retning.
Noen av forbedringene viste seg å være enkle justeringer, som at løsningen måtte kunne svare på nynorsk der innsender hadde skrevet på nynorsk. Andre forhold var mer omfattende, som å unngå misforståelser i nært beslektede saker, der konklusjoner kunne være svært forskjellige avhengig av nyanser i sakene.
2. Dataarbeidet er den virkelige jobben
Det største arbeidet lå ikke i å justere selve språkmodellen, men i å jobbe med dataene rundt den. Mye av innholdet som fantes fra før, var naturligvis ikke skrevet med AI som sluttbruker, og måtte struktureres, renses, omskrives og tilpasses for at vi skulle finne fram til riktig informasjon og samtidig gi tilstrekkelig kontekst til å kunne svare på henvendelsene som kom inn. Logging, måling og forklarbarhet ble nødvendig for å forstå hvorfor modellen svarte som den gjorde, og hvordan den kunne forbedres.
Dataarbeidet viste seg å være både tidkrevende og kontinuerlig. Samtidig meldte brukerne om enkelte gjentakende misforståelser, og vi valgte derfor å involvere kundebehandlere direkte i produksjon av skreddersydd innhold som raskt kunne tette hullene.
Dette er ikke nødvendigvis den mest skalerbare løsningen, og den kan helt klart sies å bryte med etablert best practice. Likevel mener vi det var riktig valg for dette brukercaset. For det første ga det raskere forbedringer i kvalitet og brukeropplevelse. For det andre skapte det et tydeligere eierskap til både løsningen og dataene som ligger til grunn for svarene.
Samtidig hindrer ikke produksjon av skreddersydd innhold oss i å videreutvikle mer skalerbare datapipelines parallelt. Etter hvert som modenheten øker, kan en stadig større del av behovet dekkes av disse prosessene, og avhengigheten av egenprodusert innhold blir gradvis mindre. På sikt fases dermed behovet for manuell kuratering ut.
Vi kan akseptere noe risiko, for å lære fortere
Denne læringen kommer som en direkte konsekvens av at vi valgte å akseptere noe risiko for å komme raskt i produksjon. Vi involverte brukerne mens løsningen fortsatt gjorde mange feil, og selv etter brukertesting der flere mangler ble avdekket, valgte vi å gå videre. I starten brukte vi en ekstern modell, noe som krevde både avgrensning i hvilke saker vi kunne håndtere og ekstra mekanismer for å sikre personvern. Likevel ga dette oss tidlig og verdifull innsikt som fortsatt er relevant nå som vi skalerer og øker modenheten. Nå som hele løsningen ligger på egen infrastruktur, og vi har flere verktøy tilgjengelig i AI-verktøykassen, drar vi fortsatt nytte av erfaringene fra den tidlige fasen. Vi hadde ikke klart å realisere disse gevinstene like raskt dersom vi hadde ventet med brukerinnsikten til alt dette var på plass.
Skalering: Vertikalt er enkelt – horisontalt er vanskeligere
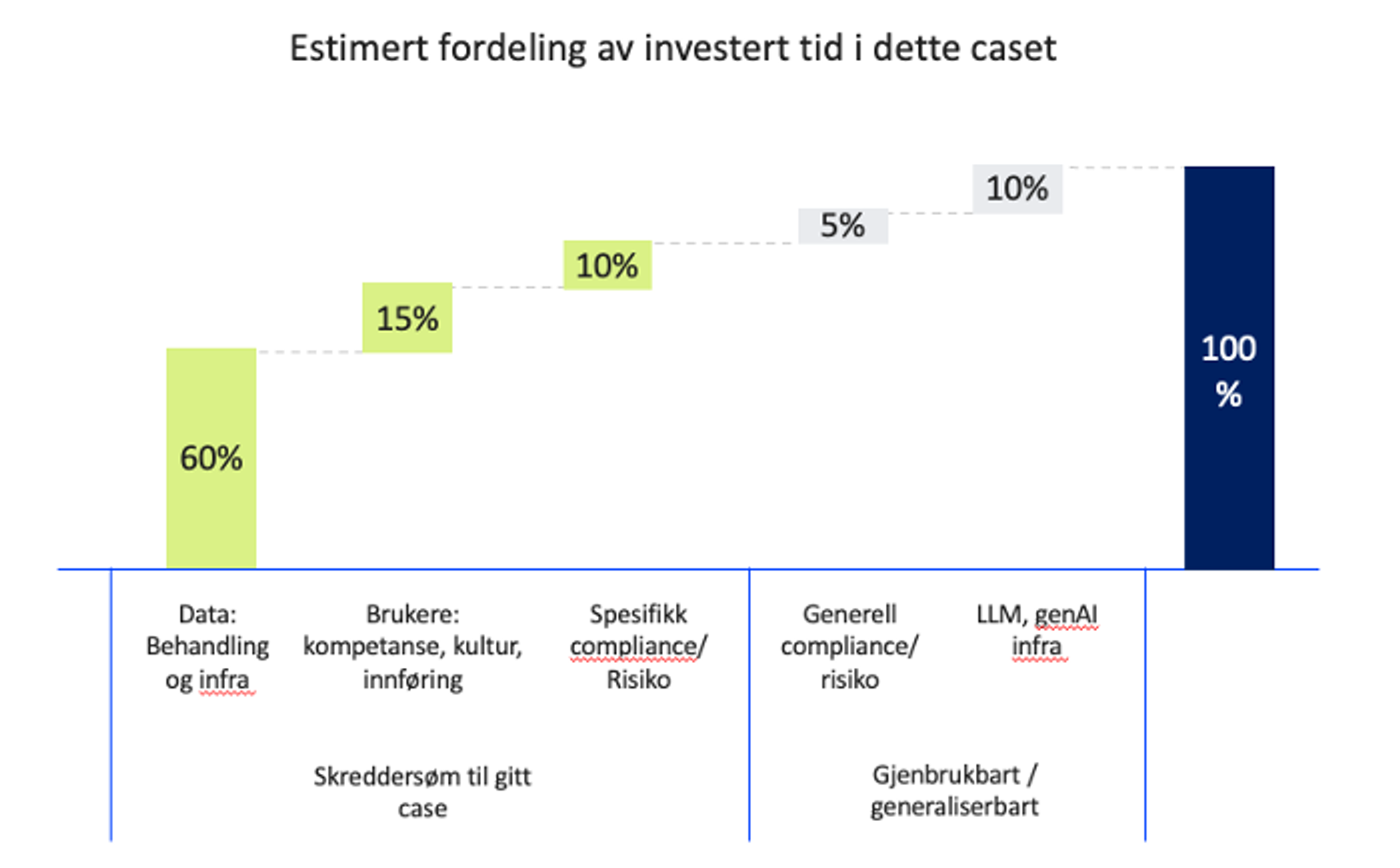
Når vi prøver å illustrere hvordan arbeidsfordelingen har vært gjennom prosjektet, ser vi hvor stor andel av tiden som har gått til arbeid med data. Selv om en god del av arbeidet knyttet til infrastruktur, generell compliance og generativ AI-utvikling er gjenbrukbart, erfarer vi at mesteparten av innsatsen likevel går med til skreddersydde oppgaver for det konkrete brukercaset og domenet.
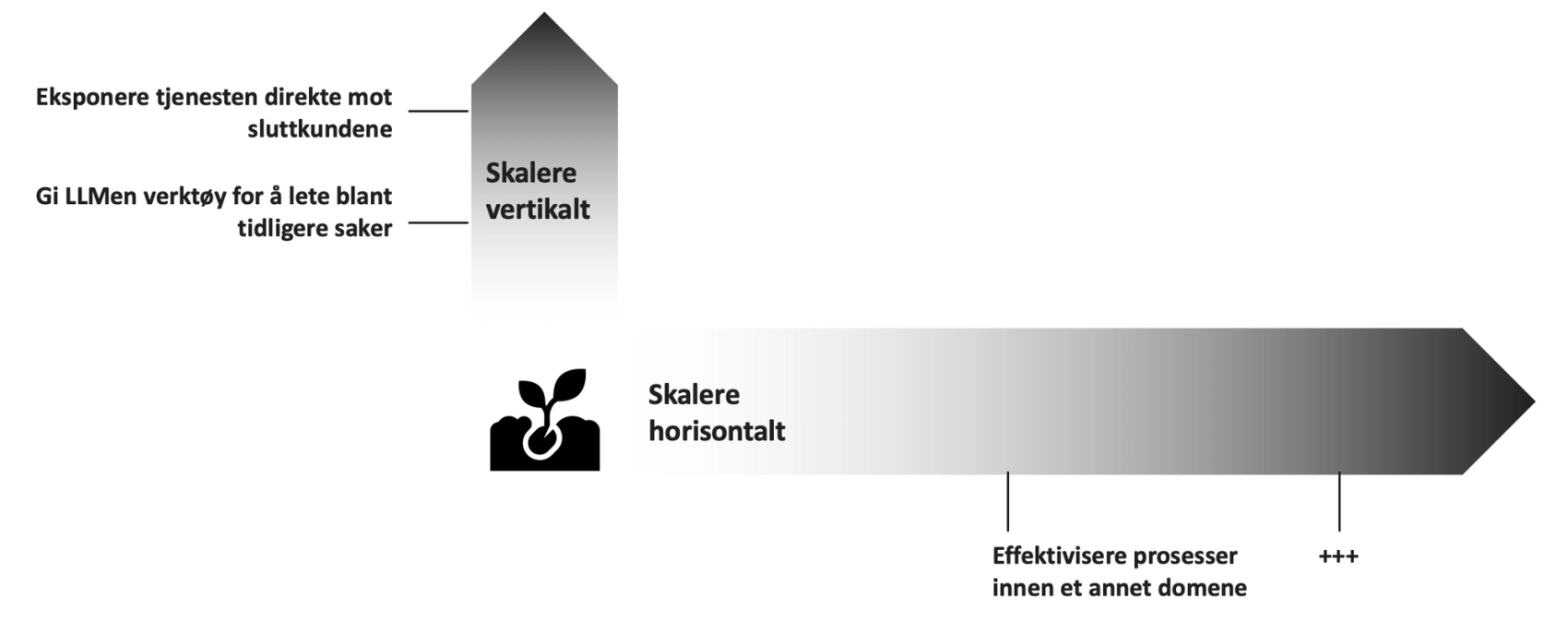
Vertikal skalering – bygge mer innen samme domene
Med vertikal skalering mener vi å videreutvikle løsningen innenfor samme domene. Dette kan for eksempel være å bygge løsningen slik at den, innenfor et avgrenset bruksområde, kan eksponeres direkte mot sluttbrukeren. Et annet eksempel er å tilgjengeliggjøre verktøy som gjør at løsningen kan søke i tidligere saker. Utvidelsene i seg selv er ikke nødvendigvis enkle, men når skaleringen skjer innenfor samme domene, blir den langt mer håndterbar for ett og samme team.
Horisontal skalering – ta AI til andre deler av organisasjonen
Horisontal skalering handler om å ta AI inn i nye domener. Selv om man kan ha opparbeidet seg svært gode erfaringer og gjenbrukbare komponenter fra tidligere arbeid, står man likevel overfor et nytt domene der man i stor grad starter fra scratch. Hvis vi aksepterer påstanden om at det ikke-overførbare arbeidet med data, brukere og domene- og compliance-spesifikke problemstillinger utgjør rundt 80 % av innsatsen, blir det raskt tydelig at det ikke skal mange nye initiativer til før det blir uhåndterbart for ett enkelt AI-team.
Før man starter et nytt case, bør man derfor stille følgende spørsmål:
• Finnes det et team som faktisk eier problemet?
• Har de kompetanse til å overta og videreutvikle AI-løsningen?
• Har vi kontroll på datakvalitet og eierskap?
• Er gevinsten stor nok og i tråd med langsiktige prioriteringer
Hva kreves egentlig av en organisasjon som vil lykkes med AI?
Når vi nå skal skalere med AI, skjærer det seg ut noen ganske tydelige hensyn vi må ta for å lykkes. Vi sitter med mye kompetanse, både teknisk og faglig, men vi vet også at det å gå inn i nye domener er svært krevende, i stor grad fordi arbeidet med data er den største tidsdriveren.
Brukerinvolvering er derfor helt kritisk, fordi det er brukerne som sitter med domeneekspertisen og kjenner hvilke prosesser der effektivisering vil skape verdi. Samtidig krever dette en tydelig satsing fra organisasjonen, slik at eierskap til data, og som en konsekvens til løsningene, kan ligge hos de aktuelle brukerne.
I noen tilfeller handler det om effektivisering i prosesser der et utviklerteam allerede forvalter løsningen, og der teamet selv kan eie deler av den tekniske AI-implementasjonen. Dette kan for eksempel være teknisk brukerstøtte for et av organisasjonens kjernesystemer.
I andre tilfeller handler det om å effektivisere interne prosesser der brukerne ikke kan eie en teknisk implementasjon, men likevel være direkte involvert i utforming, vurdering og utbedring av datakildene som inngår i løsningen. Dette kan for eksempel være støtte i å identifisere og belyse ulik praksis i tilgjengelige kilder hos jurister.
Eller kanskje må man begynne å produsere innhold for kundesenteret og på nettsidene sine, med tanke på at det mest sannsynlig skal tilgjengeliggjøres og benyttes i en AI-løsning.
Dette er ulike prosesser, med forskjellige tilnærminger til hvordan man kan komme nærmere en mer håndterbar forvaltning av AI. Likevel er fellesnevneren den samme: data, og behovet for å tenke strategisk om eierskap og forvaltning, slik at det blir en strategisk ressurs som muliggjør innovasjon i organisasjonen.